




“D&A leaders must take pragmatic and targeted actions to improve their enterprise data quality if they want to accelerate their organisations’ digital transformation”, says Gartner, whose recent research estimates that poor data quality costs organisations an annual average $12.9 million.
The technological research firm argues that, in addition to the immediate negative effect on revenue, the long-term effects of poor quality data can increase the complexity of data ecosystems and lead to poor decision making.
In this article we'll discuss what defines "good" versus poor data quality, what leads to poor data quality, the impact and costs of poor data quality, and how investing in data engineering can improve and prevent poor data quality.
Defining good data quality
On a surface level, determining the quality of data might seem straightforward—-either it’s accurate or inaccurate, right?
Unfortunately, it’s not so simple. Grow posits that data (and especially big data) can have a variety of quality issues that extend beyond mere accuracy. In fact, there are seven dimensions to consider when evaluating data quality.
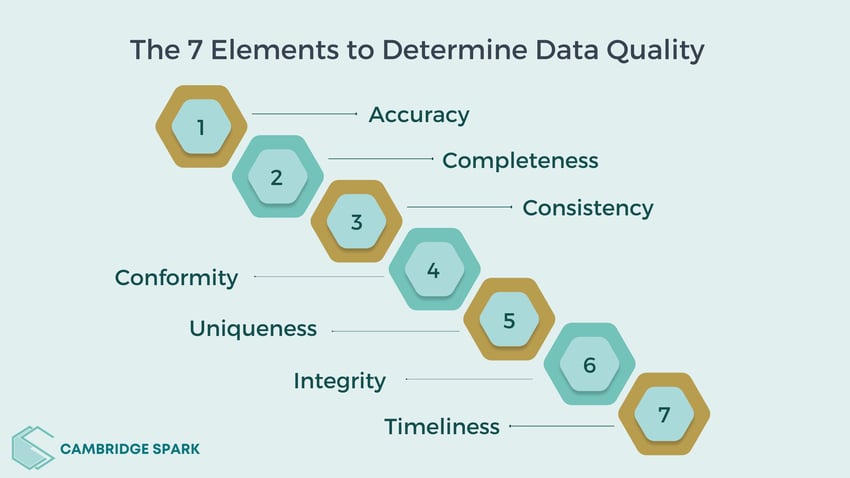
The 7 elements to determine data quality
1. Accuracy
Very simply, each field's values in a database must be accurate representations of "real world" values, meaning the information must be true as discussed above.
E.g. names should be spelled correctly, addresses should be real addresses, sales totals should reflect the correct number of sales made.
2. Completeness
The data should include all required and anticipated information, and the user should be able to understand the range of each data element. There shouldn't be any useless or missing components.
E.g. a form can still be deemed complete even if the middle name is not entered if only the first and last names are required.
3. Consistency
All systems and the company as a whole should use the same recorded data. Beware of information that is contradictory across data sets, records, and systems.
E.g. sales data registered in an organisation's CRM should match the sales data recorded in any accounting software.
4. Conformity
Data should adhere to predetermined standards for type, size, format, etc.
E.g. dates should all be recorded using the same format, digits, not letters should be used for recording numbers.
5. Uniqueness
A single, real-world entity should only have one corresponding entry in your database. Remove any duplicate entries.
E.g. if you have two entries representing a single person with slight variations in the spelling of their name, remove the incorrect one.
6. Integrity
There should be recorded relationships connecting all the data, ensuring that it is legitimate across all links. Keep in mind that unlinked records may cause duplicate entries in your system.
E.g. if a database entry for an address contains no information about the person, business, or other relationship that might be connected to it, the data is invalid. This record is orphaned.
7. Timeliness
The user should be able to access the data when they need and expect it. User expectations determine whether info is timely.
E.g. in contrast to a billing system, which may only require updating once per day, a hotel booking website typically must update availability records in real time.
Now that we have a good understanding of what constitutes good quality data, why is it important and what leads to poor quality data?
For policy and decision-making, high-quality data is crucial, and it also supports your organisation's strategic goals. Poor quality data that is erroneous, lacking, or out of date is unfit for use. It can also heighten risk and cost you money and time.
👉RECOMMENDED READING: 
What leads to poor data quality?
Bad data can enter your system through a variety of channels, but they all primarily arise from two factors: human error and technical difficulties.
Human error
The vast majority of problems with data quality are due to simple human error. For example, employees may accidentally enter errors into the system due to distraction, miscommunication, or typos, which introduces inaccuracy into the system.
Similar issues might arise when staff members enter data inconsistently or incompletely, violating business policies. Or, there may be a uniqueness problem if numerous employees collect information about the same person or business but enter it in a different way, leading to duplicates.
Outside of employees, there are many other ways data can be input incorrectly. Any data entry by clients, prospects, or others outside of your organisation may also lead to issues. For instance, if you use lead forms, a prospective client can read a field's purpose incorrectly, or submit their information slightly differently than they did the first time.
Data that was once entered correctly can also become outdated over time, which is a factor that neither people nor systems can control. A customer might relocate, the firm contact might change positions, etc. These inevitable changes can cause once accurate data to gradually decay.
Technical difficulties
Aside from human error, issues with data quality are usually brought on by the technologies organisations regularly use. Most organisations rely on a variety of software platforms and systems to operate. And organisations will have inconsistent versions of the "truth" when those systems aren't integrated effectively.
For example, there is unavoidable risk to data quality whenever an organisation switches systems (CRMs, campaign management platforms, finance software, etc.) and has to move its current data to the new platform.
Data may get lost or become distorted during the migration. Additionally, as humans provide the final evaluation for the majority of system migrations, there is an added chance for human error to occur.
Platform updates are another source of data quality problems. The platform's initial designers understand why and how user data is handled. Whereas new or outside developers are frequently more interested in functionalities than how those features will affect the data. Data integrity may be impacted with new modifications.
Finally, as much as we might design them reliability in mind, complex software systems aren’t without ongoing faults. The more complicated the system, the greater chance for system faults to cause issues with data quality.
👉RECOMMENDED READING: 
The organisational impact of poor data quality
Poor data quality wastes time
Inaccurate or mismanaged data can often be a huge drain on resources in every department, from data scientists and engineers to end users of data like salespeople. Data engineers spend much of their time validating, tidying up, correcting, or even completely ditching and reworking data.
They often then spend extra time on top of that seeking further information they require that wasn’t collected in the first place. Because machine learning and data quality go hand in hand, fewer machine learning models are tested and deployed in the end.
As a result, getting the correct data to the right people in a usable format is one of the most difficult challenges for any data-driven company. This is a common issue among businesses because, as they grow, data is migrated and distributed to various applications, systems, and departments leaving its integrity vulnerable to all of the elements discussed above.
Higher data quality enables organisations to present data that is immediately usable, saving time. Instead of waiting for data to be validated and usable, decision-makers can react to problems and market developments immediately. And as the business expands, higher data quality will make it simpler to automate data integration, ensuring that data quality is maintained when data is transferred across applications and systems.
Poor data quality leads to reputational damage
Poor data quality is not only a financial issue; it can also harm a company's reputation. According to Gartner, organisations continue to experience inefficiencies, increased costs, compliance risks, and client satisfaction challenges as a result of making (often incorrect) assertions about the state of their data. In essence, company data quality in their company goes unmanaged.
Customer dissatisfaction has a detrimental impact on a company's reputation since unhappy consumers can vent their frustrations via word of mouth or online using social media platforms, for example. And when data inconsistencies go uncorrected, employees may begin to doubt the accuracy of the underlying data as well. They might even request a customer's validation of their data while they are interacting with them, which lengthens handling times and further damages customer confidence.
Poor data quality leads to missed opportunities
Poor data quality may also cause business to miss important opportunities or hamper the delivery of services. For instance, using outdated or incorrect data may lead to the delivery of services that are redundant in one location, whereas using high-quality data could have revealed more advantageous opportunities.
Poor data quality can also prevent organisations from assessing their own effectiveness and determining whether money and resources are being put to the best use. High-quality data can lead to more focused corporate objectives, more advantageous use of company funds, and improved organisational efficiency.
How to improve data quality at your organisation
It's unlikely that worries about data quality will get any better in the future. Big data will continue to grow, and the systems that support it will get more and more complex, even with the aid of cutting-edge data validation tools and machine learning. Businesses will soon be overcome by data issues if they don't take action to address them.
Passive data quality improvement is not a runner. The only way to avoid the potential harm that inaccurate data can do is to proactively fix any problems that already exist in the company’s data and systems, stop new errors from being added, and change the attitude and culture surrounding data in the business.
Invest in quality data architecture and management
To avoid the risks described above, businesses must adopt a data-driven mindset and invest in their data teams. Though an organisation might be able to discover a data quality software solution that fits its demands, depending on the severity of its issues, for many organisations it might make more sense to hire or internally upskill existing professionals to handle ongoing data management tasks.
To ensure a company’s ongoing data integrity from day dot, establishing a solid data architecture is a must. This necessitates skilled data engineers with the requisite technical and leadership abilities to assist business functions in the creation and maintenance of quality data analytics pipelines.
👉RELATED READING: 
Take preventative measures
Improving the quality of existing data is all well and good, but wouldn’t it be better to prevent poor quality data in the first place?
If an organisation hasn't established guidelines for data entry processes, or if rules have become obsolete as the company has grown, the organisation should take some time to review the existing issues and see if there are any guidelines that can be developed or rules within the system that can be implemented that will prevent future collection of incomplete or bad data.
Foster a data-driven company culture
For many businesses, improving data quality entails more than just correcting system errors.The organisations that are most likely to succeed in continuing to generate high quality data that is useful to them, are those that adopt a data-positive culture that is driven from the top of the organisation.
When the leadership team and key stakeholders commit to a data-driven culture and demonstrate this commitment by continuously measuring and improving data quality, celebrating key data milestones, investing in and upskilling existing employees with up-to-date data skills and knowledge - this new culture will begin to permeate and trickle down throughout the entire organisation.
Want to take your organisation’s data capabilities to the next level?
As a leading AI and data science capability partner, here at Cambridge Spark we offer multiple training and apprenticeships programmes designed to upskill your employees to be able to handle all aspects of your company’s data architecture.
Fill out the form below to find out more about our programmes.