
What is XGBoost?
XGBoost stands for Extreme Gradient Boosting, it is a performant machine learning library based on the paper Greedy Function Approximation: A Gradient Boosting Machine, by Friedman. XGBoost implements a Gradient Boosting algorithm based on decision trees.
The gradient boosting algorithm
If you are already familiar with Random Forests, the Gradient Boosting algorithm implemented in XGBoost is also an ensemble of decision trees. Those trees are poor models individually, but when they are grouped they can be really performant.
The difference between XGBoost and Random Forest lies in the way those trees are built and combined. Random Forest builds fully grown decision trees in parallel on subsamples of the data. Each tree is higly specialized to predict on its subsample and do not generalize well (high variance). By combining the predictions made by each individual tree, the Random Forest algorithm decreases variance and gives good performance.
XGBoost on the other hand, builds really short and simple decision trees iteratively. Each tree is called a “weak learner” for their high bias. XGBoost starts by creating a first simple tree which has poor performance by itself. It then builds another tree which is trained to predict what the first tree was not able to, and is itself a weak learner too. The algorithm goes on by sequentially building more weak learners, each one correcting the previous tree until a stopping condition is reached, such as the number of trees (estimators) to build.
Why should you learn to use XGBoost?
XGBoost is widely used in Machine Learning and got particularly famous on Kaggle, the machine learning competition website. As Anthony Goldbloom CEO of Kaggle said back in 2016, when XGBoost was becoming big in competitive Machine Learning:
It has almost always been ensembles of decision trees that have won competitions. It used to be random forest that was the big winner, but over the last six months a new algorithm called XGboost has cropped up, and it’s winning practically every competition in the structured data category.
XGBoost has shown a great track record of high performances on problems involving structured data and thus should be part of your data scientist toolbox, even more so if you are willing to compete on Kaggle. Apart from its performance, XGBoost is also recognized for its flexibility and speed. Whilst gradient boosting requires to build trees one by one sequentially, XGBoost implements a way to parallelize the training of each tree, making the training faster and the job of Data Scientists easier. XGBoost can be used with a simple SKlearn API (used in this tutorial) or a more flexible native API (used in the upcoming advanced tutorial). It is also available for other languages such as R, Java, Scala, C++, etc. and can run on distributed environments such as Hadoop and Spark.
A word of warning before going further with the tutorial, as it is well known, there is no free lunch in Machine Learning, and XGBoost is no exception to this rule. It can sometimes be harder to tune or have a higher tendency to overfitting than a simpler model such as Random Forest and perform poorly with non structured data.
Getting started
XGBoost for Python is available on pip and conda, you can install it with the following commands:
With pip: pip install --upgrade xgboost
With Anaconda: conda install xgboost
The repository can also be directly cloned from Github
Note for Windows users: with some versions of Windows, the installation with pip might not work, if it’s the case you will need to build the library from Github. See link for Github repository above and instructions here or here
Note for MacOS users: you will need to install additional packages, see instructions here
For this tutorial you will also need pandas (with xlrd to load data in xls format) and scikit-learn
pip install --upgrade pandas xlrd scikit-learn
And matplotlib with graphviz to visualize our results
pip install --upgrade matplotlib graphviz
Presentation of the dataset and problem
The data used for this tutorial can be downloaded online: https://archive.ics.uci.edu/ml/datasets/default+of+credit+card+clients.
This dataset contains information about credit card owners in Taiwan. It contains some demographics features, past payments, bills amount, etc. The last column is the target, whether or not the customer will default payment on the next month. Here is a more thorough description of the features:
This research employed a binary variable, default payment (Yes = 1, No = 0), as the response variable. This study reviewed the literature and used the following 23 variables as explanatory variables:
X1: Amount of the given credit (NT dollar): it includes both the individual consumer credit and his/her family (supplementary) credit.
X2: Gender (1 = male; 2 = female).
X3: Education (1 = graduate school; 2 = university; 3 = high school; 4 = others).
X4: Marital status (1 = married; 2 = single; 3 = others).
X5: Age (year).
X6 — X11: History of past payment. We tracked the past monthly payment records (from April to September, 2005) as follows: X6 = the repayment status in September, 2005; X7 = the repayment status in August, 2005; . . .;X11 = the repayment status in April, 2005. The measurement scale for the repayment status is: -1 = pay duly; 1 = payment delay for one month; 2 = payment delay for two months; . . .; 8 = payment delay for eight months; 9 = payment delay for nine months and above.
X12-X17: Amount of bill statement (NT dollar). X12 = amount of bill statement in September, 2005; X13 = amount of bill statement in August, 2005; . . .; X17 = amount of bill statement in April, 2005.
X18-X23: Amount of previous payment (NT dollar). X18 = amount paid in September, 2005; X19 = amount paid in August, 2005; . . .;X23 = amount paid in April, 2005.
First round of training
Quick processing
<code></code>
# Use pandas to load the data in a dataFrame import pandas as pd df = pd.read_excel('datasets/credit/default of credit card clients.xls', header=1, index_col=0)
df.head()
df.shape (30000, 24)
As it happens sometimes with public datasets, the data is not perfectly clean and some columns have unexpected values, some customers have an education equal to 5 or 6, which does not map to anything, or a payment status equal to -2… Usually those inconsistencies should be investigated and cleaned, but since the focus of this tutorial is on xgboost, we will just remove them from our dataset.
<code></code>
def process_categorical_features(df): dummies_education = pd.get_dummies(df.EDUCATION, prefix="EDUCATION", drop_first=True) dummies_marriage = pd.get_dummies(df.MARRIAGE, prefix="MARRIAGE", drop_first=True) df.drop(["EDUCATION", "MARRIAGE"], axis=1, inplace=True) return pd.concat([df, dummies_education, dummies_marriage], axis=1) df = process_categorical_features(df)
df.head()
Some features are categorical so we will need to create dummy variables before passing the data to xgboost. This is easily done with pandas’ get_dummies method.
<code></code>
def process_categorical_features(df): dummies_education = pd.get_dummies(df.EDUCATION, prefix="EDUCATION", drop_first=True) dummies_marriage = pd.get_dummies(df.MARRIAGE, prefix="MARRIAGE", drop_first=True) df.drop(["EDUCATION", "MARRIAGE"], axis=1, inplace=True) return pd.concat([df, dummies_education, dummies_marriage], axis=1) df = process_categorical_features(df)
df.head()
We dropped columns EDUCATION and MARRIAGE to replace them by dummy variables, encoding each possible value. We do not need to do it for SEX as it is already a binary variable. The encoding for the payment variables (PAY_N) is not perfect either, as a positive number refers to the number of months late and -1 refers to a payment in due time. Ideally, we should process it too, but we will assume here that it means the payment was done the month before, so the continuous variable makes sense.
Prepare training and test datasets
Let’s extract the target from the features
<code></code>
y = df['default payment next month'] X = df[[col for col in df.columns if col!="default payment next month"]]
<code></code>
<code></code>
<code></code>
<code></code>
The function train_test_split from sklearn allows easy random split of a dataset
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=.25, random_state=42)
print("Size of train dataset: {} rows".format(X_train.shape[0])) print("Size of test dataset: {} rows".format(X_test.shape[0]))
Size of train dataset: 17391 rows Size of test dataset: 5797 rows
It's now ready to train!
import xgboost as xgb
For this tutorial, we are going to use the sklearn API of xgboost, which is easy to use and can fit in a large machine learning pipeline using other models from the scikit-learn library
We set nthread to -1 to tell xgboost to use as many threads as available to build trees in parallel.
classifier = xgb.sklearn.XGBClassifier(nthread=-1, seed=42)
Let’s train a model with the default parameters. We will learn in a future tutorial how to select the best hyperparameters to improve accuracy.
classifier.fit(X_train, y_train) XGBClassifier(base_score=0.5, colsample_bylevel=1, colsample_bytree=1, gamma=0, learning_rate=0.1, max_delta_step=0, max_depth=3, min_child_weight=1, missing=None, n_estimators=100, nthread=-1, objective='binary:logistic', reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=42, silent=True, subsample=1)
Evaluation
Let’s use our trained model to predict whether the customers from the test set will default or not and evaluate the accuracy of our model.
<code></code>
predictions = classifier.predict(X_test)
<code></code>
<code></code>
Predictions are returned in a numpy array. Let’s convert it to a DataFrame for better visualisation.
pd.DataFrame(predictions, index=X_test.index, columns=['Predicted default']).head()
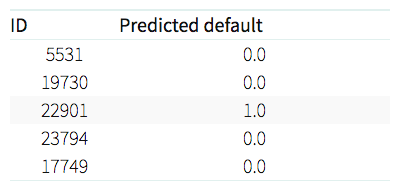
We predict that customers #5531 will not default payment next month, whilst customer #22901 will default.
pd.DataFrame(y_test).head()
Looking at the true default outcome, it turns out our model is right for those 5 first customers!
Let’s use the score xgboost method to see how accurate our model is for all test customers:
print("Model Accuray: {:.2f}%".format(100*classifier.score(X_test, y_test))) Model Accuray: 82.58%
We get a decent accuracy of over 80%.
But as a good data scientist, you should take it with a pinch of salt. The problem we are working on here is unbalanced: most of the people do not default payments and the customers who default are rare in our dataset. This means that by predicting that none of the customers will default, we could get good accuracy too, even though the model would be useless. There are ways to prevent our model to make such mistakes.
Handy XGBoost methods
XGBoost comes with a set of handy methods to better understand your model
%matplotlib inline import matplotlib.pyplot as plt
The plot_importance function allows to see the relative importance of all features in our model. Here we see that BILL_AMT1 and LIMIT_BAL are the most important features whilst sex and education seem to be less relevant
plt.figure(figsize=(20,15)) xgb.plot_importance(classifier, ax=plt.gca())

Plot_tree allows to visualize the trees that were built by XGBoost.
plt.figure(figsize=(20,15)) xgb.plot_tree(classifier, ax=plt.gca())

You can also access the characteristics of your model.
print("Number of boosting trees: {}".format(classifier.n_estimators)) print("Max depth of trees: {}".format(classifier.max_depth)) print("Objective function: {}".format(classifier.objective)) Number of boosting trees: 100 Max depth of trees: 3 Objective function: binary:logistic
As you can see, there are many parameters that define your model. Those parameters can be set before training, and selecting the good values will boost the performance of your model. We go through ways of doing so in the next tutorial.
Looking to kick-start your data science career?
Learn more about how to get started and about the Applied Data Science Bootcamp
We'll email you within the next working day to arrange a chat to help with any questions you have about getting started in data science, about the bootcamp and recommend pre-course materials to get you up to speed.
We look forward to speaking with you.

Written by Kevin Lemagnen, CTO, Cambridge Spark